| For feedback and comments: |
| documentation.feedback@alcatel-lucent.com |
|
|
|
|
|
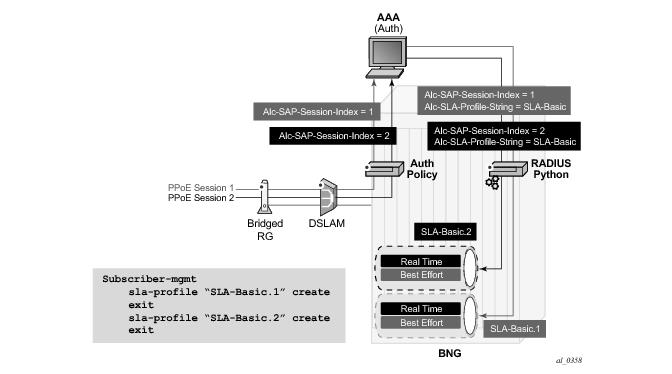
include-radius-attribute
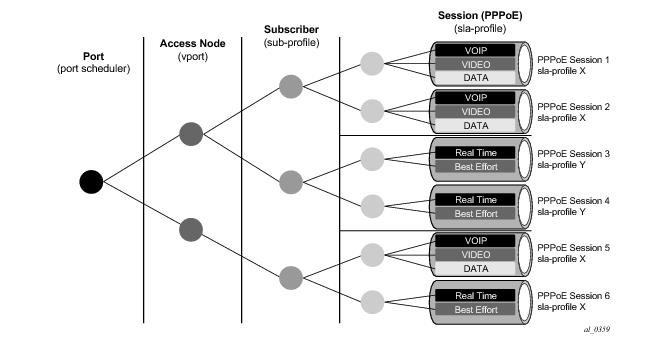
[no] sap-session-indexFigure 26: Per PPPoE Session SLA Profile Selectionimport alcimport structfrom alc import radiusfrom alc import sub_svcPROXY_STATE = 33ALU = 6527SLA_PROF_STR = 13SAP_SESSION_INDEX = 180#################################### QoS for Multiple PPPoE Sessions# This script checks if a sap-session-index (sid) is included in the authentication# accept. If present, the sla-profile-string (sla) is adapted to "sla.sid"if alc.radius.attributes.isVSASet(ALU,SLA_PROF_STR):sla = alc.radius.attributes.getVSA(ALU,SLA_PROF_STR)if alc.radius.attributes.isVSASet(ALU,SAP_SESSION_INDEX):ssi = alc.radius.attributes.getVSA(ALU,SAP_SESSION_INDEX)suffix = "" .join(["%x" % ord(x) for x in ssi])alc.radius.attributes.setVSA(ALU,SLA_PROF_STR,sla + '.' + "%d" % int(suffix,16))